 هرچقدر هم که ممکن است عجیب به نظر برسد، دیدن چند مورد false positive گزارششده توسط یک اسکنر امنیتی احتمالاً نشانه خوبی است و مطمئناً بهتر از دیدن هیچکدام است. بیایید توضیح دهیم که چرا.
هرچقدر هم که ممکن است عجیب به نظر برسد، دیدن چند مورد false positive گزارششده توسط یک اسکنر امنیتی احتمالاً نشانه خوبی است و مطمئناً بهتر از دیدن هیچکدام است. بیایید توضیح دهیم که چرا.
مقدمه
موارد false positive در سالهای اخیر تا حدودی غیرمنتظره در زندگی ما ظاهر شده است. البته منظور من به همهگیری COVID-19 است که به کمپینهای آزمایشی گسترده برای کنترل شیوع ویروس نیاز داشت. برای ثبت، false positive نتیجهای است که مثبت به نظر میرسد (در مورد ما برای COVID-19)، جایی که درواقع منفی است (فرد آلوده نیست). معمولاً از هشدارهای نادرست صحبت میکنیم.
در امنیت کامپیوتر نیز اغلب با موارد false positiveمواجه هستیم. از تیم امنیتی پشت هر SIEM بپرسید که بزرگترین چالش عملیاتی آنها چیست، و احتمال اینکه موارد false positive ذکر شود وجود دارد. یک گزارش اخیر[۱] تخمین میزند که ۲۰ درصد از تمام هشدارهای دریافت شده توسط متخصصان امنیتی، false positiveها هستند، که آن را به منبع بزرگی برای خستگی تبدیل میکند.
بااینحال، داستان پشت نکات false positiveها به آن سادگی که در ابتدا به نظر میرسد نیست. در این مقاله، ما از این موضوع حمایت خواهیم کرد که هنگام ارزیابی یک ابزار تجزیهوتحلیل، مشاهده نرخ متوسطی ازfalse positiveها نشانه نسبتاً خوبی از کارایی است.
دقیقاً در مورد چه چیزی صحبت میکنیم؟
با تجزیهوتحلیل استاتیک[۲] در امنیت برنامه، نگرانی اصلی ما این است که با تجزیهوتحلیل کد منبع، تمام آسیبپذیریهای واقعی را شناسایی کنیم.

در اینجا تصویری برای درک بهتر تمایز بین دو مفهوم اساسی تحلیل استاتیک وجود دارد: دقت[۳] و یادآوری[۴]. ذرهبین نمونهای را نشان میدهد که توسط ابزار تشخیص شناسایی یا انتخاب شده است. در اینجا[۵] میتوانید درباره نحوه ارزیابی عملکرد یک فرآیند آماری اطلاعات بیشتری کسب کنید.
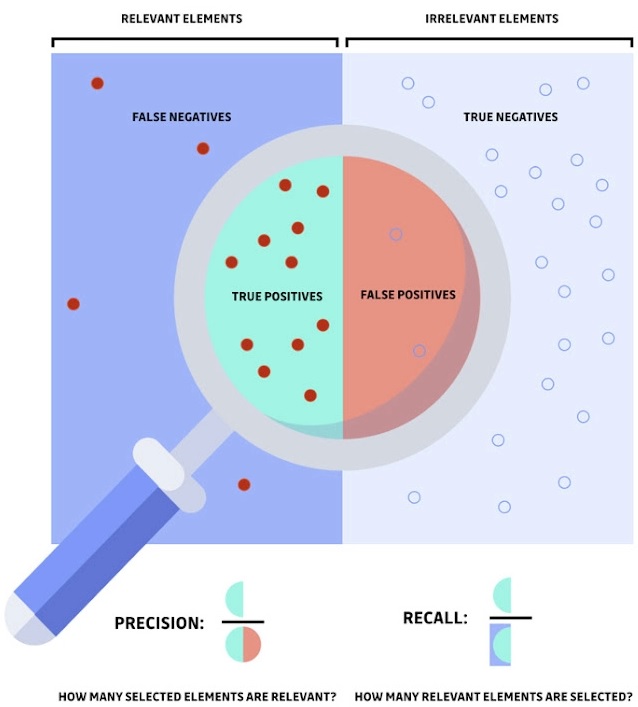
بیایید ببینیم که این ازنقطهنظر مهندسی به چه معناست:
- با کاهش false positiveها، دقت را بهبود میبخشیم (همه آسیبپذیریهای شناسایی شده درواقع یک مشکل امنیتی را نشان میدهند).
- با کاهش false negativeها، یادآوری را بهبود میبخشیم (همه آسیبپذیریهای موجود بهدرستی شناسایی میشوند).
- در فراخوان ۱۰۰ درصد، ابزار تشخیص هرگز آسیبپذیری را از دست نمیدهد.
- با دقت ۱۰۰ درصد، ابزار تشخیص هرگز هشدار نادرست ایجاد نمیکند.
بهعبارتدیگر، هدف اسکنر آسیبپذیری این است که دایره (در ذرهبین) را تا حد امکان به مستطیل سمت چپ (عناصر مربوطه) نزدیک کند.
مشکل این است که پاسخ بهندرت واضح است، به این معنی که باید مبادلاتی انجام شود.
بنابراین، چه چیزی مطلوبتر است: به حداکثر رساندن دقت یا یادآوری؟
کدامیک بدتر است، false positiveهای زیاد یا false negativeهای زیاد؟
برای درک دلیل، بیایید آن را به هر دو حالت افراطی ببریم: تصور کنید که یک ابزار تشخیص تنها زمانی به کاربران خود هشدار میدهد که احتمال اینکه یک قطعه کد معین حاوی یک آسیبپذیری باشد از ۹۹٫۹۹۹% بالاتر باشد. با چنین آستانه بالایی، تقریباً میتوانید مطمئن باشید که یک هشدار واقعاً یک true positive است. اما چه تعداد از مشکلات امنیتی به دلیل انتخابی بودن اسکنر موردتوجه قرار نمیگیرد؟ زیاد.
حال، برعکس، چه اتفاقی میافتد اگر ابزار بهگونهای تنظیم شود که هرگز آسیبپذیری را از دست ندهد (به حداکثر رساندن فراخوانی)؟ درست حدس زدید: بهزودی با صدها یا حتی هزاران هشدار نادرست مواجه خواهید شد و خطر بزرگتری وجود دارد.
همانطور که Aesop در افسانه The Boy Who Cried Wolf به ما هشدار داد[۶]، هرکسی که فقط ادعاهای نادرست را تکرار کند، درنهایت به او گوش داده نمیشود. در دنیای مدرن ما، ناباوری بهعنوان یک کلیک ساده برای غیرفعال کردن اعلانهای امنیتی و بازگرداندن صلح و آرامش ظاهر میشود، یا اگر غیر فعالسازی مجاز نباشد، آنها را نادیده میگیرد. اما عواقب آن میتواند حداقل به همان اندازه دراماتیک باشد که در افسانه وجود دارد.
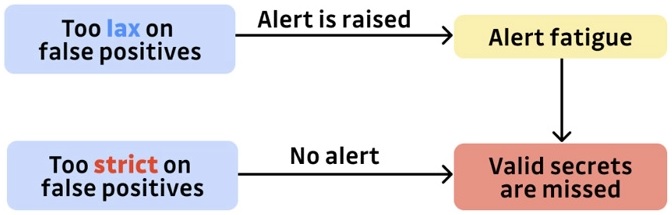
منصفانه است که بگوییم خستگی هشدار احتمالاً دلیل شماره یک شکست تحلیل استاتیک است. هشدارهای کاذب نهتنها منشأ خرابی کل برنامههای امنیتی برنامه هستند، بلکه باعث آسیبهای بسیار جدیتری مانند فرسودگی و مشارکت میشوند.
و بااینحال، باوجود تمام بدیهایی که به آنها نسبت داده میشود، اشتباه میکنید که فکر کنید اگر ابزاری دارای هیچ false positive ای نیست، پس باید پاسخ قطعی برای این مشکل بیاورد.
چگونه یاد بگیریم که false positiveها را بپذیریم؟
برای پذیرش false positiveها، باید برخلاف آن غریزه اساسی که اغلب ما را به سمت نتیجهگیریهای اولیه سوق میدهد، برویم. یک آزمایش فکری دیگر میتواند به ما در توضیح این موضوع کمک کند.
تصور کنید که وظیفه مقایسه عملکرد دو اسکنر امنیتی A و B را دارید.
پس از اجرای هر دو ابزار در معیار خود، نتایج به شرح زیر است: اسکنر A فقط آسیبپذیریهای معتبر را شناسایی کرد، درحالیکه اسکنر B آسیبپذیریهای معتبر و نامعتبر را گزارش کرد. در این مرحله، چه کسی وسوسه نمیشود که یک نتیجهگیری زودهنگام بگیرد؟ شما باید بهاندازه کافی ناظر عاقل باشید که قبل از تصمیمگیری اطلاعات بیشتری را بخواهید. دادهها بهاحتمالزیاد نشان میدهد که برخی از اسرار معتبر گزارششده توسط B توسط A بیسروصدا نادیده گرفته شده است.
اکنون میتوانید ایده اصلی پشت این مقاله را ببینید: هر ابزار، فرآیند یا شرکتی که ادعا میکند کاملاً عاری از موارد false positive است، باید مشکوک به نظر برسد. اگر واقعاً اینطور بود، احتمال اینکه برخی از عناصر مرتبط بیسروصدا نادیده گرفته شوند بسیار زیاد بود.
یافتن تعادل بین دقت و یادآوری موضوع ظریفی است و نیاز به تلاشهای زیادی برای تنظیم دارد (شما میتوانید بخوانید که مهندسان GitGuardian چگونه دقت مدل[۷] را بهبود میبخشند). نهتنها این، بلکه کاملاً طبیعی است که گاهی شاهد شکست آن باشیم. به همین دلیل است که باید از ندیدن false positive ها بیشتر نگران باشید تا دیدن تعداد کمی از آنها.
اما دلیل دیگری نیز وجود دارد که چرا false positive ها ممکن است درواقع سیگنال جالبی نیز باشد: امنیت هرگز “همه سفید یا سیاه” نیست. همیشه حاشیهای وجود دارد که «نمیدانیم»، و جایی که بررسی و تریاژ انسانی ضروری میشود.
“به دلیل ماهیت نرمافزاری که مینویسیم، گاهی اوقات false positive دریافت میکنیم. وقتی این اتفاق میافتد، توسعهدهندگان ما میتوانند فرمی را پر کنند و بگویند: “هی، این یک false positive است. این بخشی از یک مورد آزمایشی است. شما میتوانید این را نادیده بگیرید.” – منبع[۸].
حقیقت عمیقتری وجود دارد: امنیت هرگز «همه سفید یا سیاه» نیست. همیشه حاشیهای وجود دارد که در آن «نمیدانیم» و بررسی دقیق و تریاژ انسانی ضروری میشود. بهعبارتدیگر، این فقط در مورد اعداد خام نیست، بلکه به نحوه استفاده از آنها نیز مربوط میشود. نکات false positive از این منظر مفید هستند: آنها به بهبود ابزارها و اصلاح الگوریتمها کمک میکنند تا زمینه بهتر درک و در نظر گرفته شود. اما مانند یک مجانب[۹]، هرگز نمیتوان به صفر مطلق رسید.
یک شرط ضروری برای تبدیل آنچه به نظر یک نفرین[۱۰] به نظر میرسد به یک دایره بافضیلت[۱۱] وجود دارد. شما باید مطمئن شوید که میتوان موارد false positive را بهآسانی برای کاربران نهایی پرچم گذاری کرد و در الگوریتم تشخیص گنجاند. یکی از متداولترین راهها برای دستیابی به آن، ارائه امکان حذف فایلها، دایرکتوریها یا مخازن از محیط اسکن شده است.
در GitGuardian، ما در کشف اسرار[۱۲] متخصص هستیم. ما این ایده را برای ارتقاء هر یافته با زمینهای تا حد امکان مطرح کردیم، که منجر به چرخههای بازخورد بسیار سریعتر و کاهش هر چه بیشتر کار میشود.
اگر توسعهدهندهای سعی کند یک راز[۱۳] را با ggshield سمت کلاینت[۱۴] که بهعنوان یک قلاب پیشارتکاب[۱۵] نصب شده است، مرتکب شود، ارتکاب متوقف میشود مگر اینکه توسعهدهنده آن را بهعنوان یک راز علامتگذاری کند تا نادیده گرفته شود[۱۶]. ازآنجا، راز false positive در نظر گرفته میشود و دیگر هشداری را بهجز در ایستگاه کاری محلی[۱۷] او راهاندازی نمیکند. فقط یک عضو تیم امنیتی با دسترسی به داشبورد GitGuardian میتواند یکfalse positive را برای کل تیم پرچمداری کند (نادیدهگیری سراسری).
اگر یک راز فاش شده گزارش شود، ما ابزارهایی را برای کمک به تیم امنیتی برای ارسال سریع آنها ارائه میکنیم. بهعنوانمثال، کتاب راهنمای بهبود خودکار[۱۸] بهطور خودکار یک ایمیل برای توسعهدهندهای که راز را مرتکب شده است ارسال میکند. بسته به پیکربندی کتاب راهنما، میتوان به توسعهدهندگان اجازه داد که خودشان این حادثه را حل کنند یا نادیده بگیرند و میزان کار باقیمانده به تیم امنیتی را کاهش دهند.
اینها تنها چند نمونه از این هستند که چگونه یاد گرفتیم که فرآیندهای تشخیص و اصلاح را بهجای وسواس در مورد حذف آنها، حول موارد false positive تنظیم کنیم. در آمار، این وسواس حتی یک نام هم دارد: به آن overfitting میگویند، و به این معنی است که مدل شما بیشازحد به مجموعه خاصی از دادهها وابسته است. این مدل بدون ورودیهای واقعی، در محیط تولید مفید نخواهد بود.
نتیجهگیری
false positive باعث خستگی هشدار میشود و برنامههای امنیتی را از مسیر خارج میکند، بهطوریکه اکنون بهطور گستردهای شیطان محض[۱۹] در نظر گرفته میشوند. درست است که هنگام در نظر گرفتن یک ابزار تشخیص، بهترین دقت ممکن را میخواهید، و داشتن بیشازحد false positive باعث مشکلات بیشتری نسبت به استفاده نکردن از هیچ ابزاری در وهله اول میشود. بااینحال، هرگز از نرخ فراخوان غافل نشوید.
در GitGuardian، ما زرادخانهی وسیعی از فیلترهای تشخیص عمومی[۲۰] را برای بهبود نرخ فراخوان موتور تشخیص اسرار خود طراحی کردیم.
از منظر صرفاً آماری، داشتن نرخ پایین false positive نشانه نسبتاً خوبی است، به این معنی که تعداد کمی از ایرادات از شبکه عبور میکند.
هنگام کنترل، false positive چندان بد نیست. آنها حتی میتوانند به نفع شما مورداستفاده قرار گیرند، زیرا نشان میدهند که در چه قسمتهایی میتوان پیشرفتها را انجام داد، چه در سمت تجزیهوتحلیل و چه در سمت اصلاح.
درک اینکه چرا چیزی توسط سیستم “معتبر” تلقی میشود و داشتن راهی برای انطباق با آن، کلید بهبود امنیت برنامه شما است. ما همچنین متقاعد شدهایم که این یکی از زمینههایی است که همکاری بین تیمهای امنیتی و توسعه واقعاً درخشان است.
بهعنوان نکته پایانی، به یاد داشته باشید: اگر یک ابزار تشخیص هیچ false positive ای را گزارش نکرد، فرار کنید! زیرا گرفتار دردسر بزرگی هستید!
توجه – این مقاله توسط Thomas Segura، نویسنده محتوای فنی در GitGuardian نوشته و ارائه شده است.
منابع
[۱] https://orca.security/resources/blog/2022-cloud-cyber-security-alert-fatigue-report
[2] https://blog.gitguardian.com/why-sast-dast-cant-be-enough
[3] https://blog.gitguardian.com/secrets-detection-accuracy-precision-recall-explained
[4] https://en.wikipedia.org/wiki/The_Boy_Who_Cried_Wolf
[5] https://blog.gitguardian.com/tag/secrets-detection
[6] https://www.itcentralstation.com/product_reviews/gitguardian-internal-monitoring-review-1295666-by-reviewer1692456
[7] https://orca.security/resources/blog/2022-cloud-cyber-security-alert-fatigue-report
[8] https://github.com/gitguardian/ggshield
[9] https://docs.gitguardian.com/internal-repositories-monitoring/gg_shield/configuration#ignore-list
[10] https://docs.gitguardian.com/internal-repositories-monitoring/workspace/playbooks#auto-healing-playbook
[11] https://blog.gitguardian.com/why-detecting-generic-credentials-is-a-game-changer
[12] https://thehackernews.com/2022/08/the-truth-about-false-positives-in.html
(۱) precision
(2) recall
(3) asymptote
(4) curse
(5)virtuous
(6) secret
(7) pre-commit
(8) local workstation
(9) pure evil
ثبت ديدگاه