 محققان امنیت سایبری دریافتهاند که افزونههای شخص ثالث موجود برای OpenAI ChatGPT میتوانند بهعنوان یک سطح حمله جدید برای عوامل تهدید که به دنبال دسترسی غیرمجاز به دادههای حساس هستند، عمل کند.
محققان امنیت سایبری دریافتهاند که افزونههای شخص ثالث موجود برای OpenAI ChatGPT میتوانند بهعنوان یک سطح حمله جدید برای عوامل تهدید که به دنبال دسترسی غیرمجاز به دادههای حساس هستند، عمل کند.
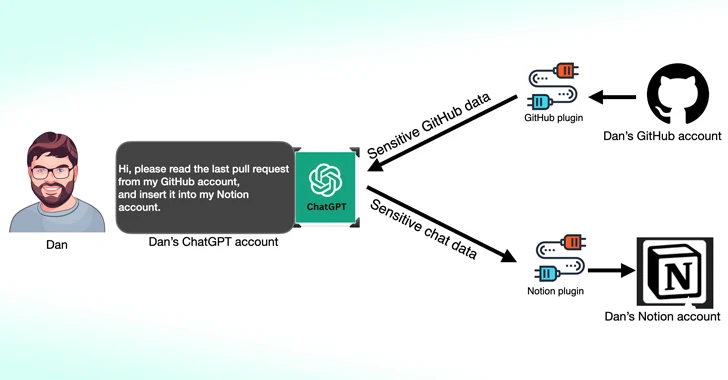
بر اساس تحقیقات جدیدی[۱] که توسط Salt Labs منتشر شده است، نقصهای امنیتی که مستقیماً در ChatGPT و در اکوسیستم یافت میشود میتواند به مهاجمان اجازه دهد تا افزونههای مخرب را بدون رضایت کاربران نصب کنند و حسابهای کاربری را در وبسایتهای شخص ثالث مانند GitHub بربایند.
افزونههای ChatGPT[2]، همانطور که از نام آن پیداست، ابزارهایی هستند که برای اجرا در بالای large language model یا LLM باهدف دسترسی به اطلاعات بهروز، اجرای محاسبات یا دسترسی به خدمات شخص ثالث طراحی شدهاند.
OpenAI از آن زمان GPTها[۳] را نیز معرفی کرده است که نسخههای سفارشی ChatGPT هستند که برای موارد استفاده خاص طراحی شدهاند و درعینحال وابستگیهای خدمات شخص ثالث را کاهش میدهند. از ۱۹ مارس ۲۰۲۴، کاربران ChatGPT دیگر نمیتوانند[۴] افزونههای جدید را نصب کنند یا مکالمات جدیدی با افزونههای موجود ایجاد کنند.
یکی از معایب کشف شده توسط Salt Labs شامل بهرهبرداری از [۵]OAuth workflow برای فریب کاربر برای نصب یک افزونه دلخواه با استفاده از این واقعیت است که ChatGPT تأیید نمیکند که کاربر واقعاً نصب افزونه را شروع کرده است.
این به طور مؤثر میتواند به عوامل تهدید اجازه دهد تا تمام دادههای به اشتراک گذاشته شده توسط قربانی را که ممکن است حاوی اطلاعات اختصاصی باشد، رهگیری و از آنها خارج کنند.
این شرکت امنیت سایبری همچنین مشکلاتی را با PluginLab کشف کرده است[۶] که میتواند توسط عوامل تهدید برای انجام حملات تصاحب حساب بدون کلیک مورداستفاده قرار گیرد و به آنها اجازه میدهد کنترل حساب یک سازمان را در وبسایتهای شخص ثالث مانند GitHub به دست آورند و به مخازن کد منبع آنها دسترسی داشته باشند.
Aviad Carmel، محقق امنیتی، در این باره توضیح داد: ” [The endpoint] “auth.pluginlab [.]ai/oauth/authorized” درخواست را تأیید نمیکند، به این معنی که مهاجم میتواند شناسه عضو دیگری (معروف به قربانی) را وارد کند و کدی را دریافت کند که نشاندهنده قربانی است. با آن کد، او میتواند از ChatGPT استفاده کند و به GitHub قربانی دسترسی پیدا کند.”
شناسه عضو قربانی را میتوان با querying در نقطه پایانی “auth.pluginlab [.]ai/members/requestMagicEmailCode.” به دست آورد. هیچ مدرکی مبنی بر اینکه اطلاعات کاربر با استفاده از این نقص به خطر افتاده باشد وجود ندارد.
همچنین در چندین افزونه، از جمله Kesem AI، یک اشکال دستکاری تغییر مسیر OAuth کشف شده است که میتواند به مهاجم اجازه دهد اعتبار حساب مرتبط با خود افزونه را با ارسال یک پیوند ساخته شده مخصوص به قربانی، بدزدد.
این توسعه هفتهها پس از آن صورت میگیرد که Imperva دو آسیبپذیری اسکریپت متقابل (XSS) را در ChatGPT شرح داد[۷] که میتوان آنها را برای به دستگرفتن کنترل هر حسابی زنجیرهای کرد.
در دسامبر ۲۰۲۳، Johann Rehberger، محقق امنیتی، نشان داد[۸] که چگونه عوامل مخرب میتوانند GPTهای سفارشی[۹] ایجاد کنند که میتوانند برای اعتبار کاربر phish کنند و دادههای دزدیده شده را به یک سرور خارجی منتقل کنند.
حمله از راه دور جدید Keylogging به دستیاران هوش مصنوعی
این یافتهها همچنین به دنبال تحقیقات جدیدی[۱۰] است که این هفته در مورد حمله کانال جانبی LLM منتشر شد که از طول رمز بهعنوان وسیلهای مخفی برای استخراج پاسخهای رمزگذاری شده از دستیاران هوش مصنوعی در وب استفاده میکند.
گروهی از دانشگاهیان از دانشگاه Ben-Gurion و آزمایشگاه تحقیقاتی Offensive AI گفتند: «LLMها پاسخها را بهعنوان مجموعهای از نشانهها (مشابه کلمات) تولید و ارسال میکنند که هر توکن هنگام تولید از سرور به کاربر منتقل میشود.»
“در حالی که این فرآیند رمزگذاری شده است، انتقال توکن متوالی یک کانال جانبی جدید را در معرض دید قرار می دهد: کانال جانبی token-length. علیرغم رمزگذاری، اندازه بسته ها می تواند طول توکن ها را آشکار کند، و به طور بالقوه به مهاجمان در شبکه اجازه می دهد اطلاعات حساس و محرمانه به اشتراک گذاشته شده در مکالمات دستیار هوش مصنوعی خصوصی را استنتاج کنند.”
این کار با استفاده از یک حمله استنتاج نشانهای انجام میشود که برای رمزگشایی پاسخها در ترافیک رمزگذاری شده با آموزش یک مدل LLM که قادر به ترجمه دنبالههای طول نشانه به همتایان sentential زبان طبیعی آنها (بهعنوانمثال متن ساده) است، انجام میشود.
بهعبارتدیگر، ایده اصلی[۱۱] این است که پاسخهای چت بلادرنگ با یک ارائهدهنده LLM را رهگیری کنیم، از سربرگهای بسته شبکه برای استنتاج طول هر نشانه، استخراج و تجزیه بخشهای متن، و استفاده از LLM سفارشی برای استنتاج پاسخ استفاده کنیم.
دو پیشنیاز کلیدی برای ازبینبردن حمله، یک کلاینت چت هوش مصنوعی است که در حالت استریم اجرا میشود و دشمنی که میتواند ترافیک شبکه بین مشتری و چت ربات هوش مصنوعی را ضبط کند.
برای مقابله با اثربخشی حمله کانال جانبی، توصیه میشود که شرکتهایی که دستیارهای هوش مصنوعی را توسعه میدهند، از padding تصادفی استفاده کنند تا طول واقعی توکنها را پنهان کنند، نشانهها را در گروههای بزرگتر بهجای انفرادی ارسال کنند، و پاسخهای کامل را بهجای ارسال بهصورت token-by-token، یکباره ارسال کنند.
محققان نتیجه گرفتند: “تعادل بین امنیت با قابلیت استفاده و عملکرد چالش پیچیدهای را ارائه میدهد که نیاز به بررسی دقیق دارد.”
منابع
[۱] https://salt.security/blog/security-flaws-within-chatgpt-extensions-allowed-access-to-accounts-on-third-party-websites-and-sensitive-data
[۲] https://openai.com/blog/chatgpt-plugins
[۳] https://openai.com/blog/introducing-gpts
[۴] https://help.openai.com/en/articles/8988022-winding-down-the-chatgpt-plugins-beta
[۵] https://thehackernews.com/2023/10/critical-oauth-flaws-uncovered-in.html
[۷] https://www.imperva.com/blog/xss-marks-the-spot-digging-up-vulnerabilities-in-chatgpt
[۸] https://thehackernews.com/2024/01/italian-data-protection-watchdog.html
[۹] https://embracethered.com/blog/posts/2023/openai-custom-malware-gpt
[۱۰] https://arstechnica.com/security/2024/03/hackers-can-read-private-ai-assistant-chats-even-though-theyre-encrypted
[۱۱] https://blog.cloudflare.com/ai-side-channel-attack-mitigated
[۱۲] https://thehackernews.com/2024/03/third-party-chatgpt-plugins-could-lead.html
ثبت ديدگاه